This component implements the algorithm described in [4] (section 2), generalized to handle different types of data, multiple features and multiple labels. It classifies a data set into a user-defined set of labels, such as ground, vegetation and buildings. A flexible API is provided so that users can classify any type of data which they can index and for which they can compute relevant features, compute their own local features on the input data set and define their own labels.
Note
This component depends on the Boost libraries Serialization and IO Streams (compiled with the GZIP dependency).
Package Organization
Classification of data sets is achieved as follows (see Figure Figure 74.1):
some analysis is performed on the input data set;
features are computed based on this analysis;
a set of labels (for example: ground, building, vegetation) is defined by the user;
a classifier is defined and trained: from the set of values taken by the features at an input item, it measures the likelihood of this item to belong to one label or another;
classification is computed itemwise using the classifier;
additional regularization can be used by smoothing either locally or globally through a Graph Cut[1] approach.
This package is designed to be easily extended by users: more specifically, features and labels can be defined by users to handle any data they need to classify.
Currently, CGAL only provides data structures to handle classification of point sets.
Data Structures
Analysis
Classification is based on the computation of local features. These features can take advantage of shared data structures that are precomputed and stored separately.
CGAL provides the following structures:
Point_set_neighborhood stores spatial searching structures and provides adapted queries for points;
Local_eigen_analysis precomputes covariance matrices on local neighborhoods of points and stores the associated eigenvectors and eigenvalues;
Planimetric_grid is a 2D grid used for digital terrain modeling.
Most of these features depend on a scale parameter. CGAL provides a method to estimate the average spacing based on a number of neighbors (see CGAL::compute_average_spacing()), which usually provides satisfying results in the absence of noise. In the presence of noise, CGAL::estimate_global_range_scale() provides an estimation of the smallest scale such that the point set has the local dimension of a surface (this method is both robust to noise and outliers, see Result).
The eigen analysis can be used to estimate normals. Note however that this analysis (based on Principal Component Analysis) might not be robust to a high level of noise. CGAL also provides more robust normal estimation functions (see for example CGAL::jet_estimate_normals()).
The following code snippet shows how to instantiate such data structures from an input PLY point set (the full example is given at the end of the manual).
Local_eigen_analysis eigen (pts, Pmap(), neighborhood.k_neighbor_query(6));
Label Set
A label represents how an item should be classified, for example: vegetation, building, road, etc. In CGAL, a label has a name and is simply identified by a Label_handle. Note that names are not used for identification: two labels in the same set can have the same name (but not the same handle).
The following code snippet shows how to add labels to the classification object.
Features are defined as scalar fields that associate each input item with a specific value. Note that in order to limit memory consumption, we use the type float for these scalar values (as well as for every floating point value in this package). A feature has a name and is identified by a Feature_handle.
CGAL provides some predefined features that are relevant for classification of point sets:
Distance_to_plane measures how far away a point is from a locally estimated plane;
Elevation computes the local distance to an estimation of the ground;
Vertical_dispersion computes how noisy the point set is on a local Z-cylinder;
Verticality compares the local normal vector to the vertical vector.
For more details about how these different features can help to identify one label or the other, please refer to their associated reference manual pages. In addition, CGAL also provides features solely based on the eigenvalues [6] of the local covariance matrix:
Simple_feature uses any property map applicable to the input range and whose value type is castable to float (useful if an additional property of the input set should be used as is, for example and intensity measurement).
In the following code snippet, a subset of these features are instantiated. Note that all the predefined features can also be automatically generated in multiple scales (see Point Set Feature Generator).
Users may want to define their own features, especially if the input data set comes with additional properties that were not anticipated by CGAL. A user-defined feature must inherit from Feature_base and provide a method value() that associates a scalar value to each input item.
The following example shows how to define a feature that discriminates points that lie inside a 2D box from the others:
// User-defined feature that identifies a specific area of the 3D
// space. This feature takes value 1 for points that lie inside the
In standard classification of point sets, users commonly want to use all predefined features to get the best result possible. CGAL provides a class Point_set_feature_generator that performs the following operations:
it estimates the smallest relevant scale;
it generates all needed analysis structures and provides access to them;
it generates all possible features (among all the CGAL predefined ones) based on which property maps are available (it uses colors if available, etc.).
Multiple scales that are sequentially larger can be used to increase the quality of the results [3]. If CGAL is linked with Intel TBB, features can be computed in parallel to increase the overall computation speed.
Note that using this class in order to generate features is not mandatory, as features and data structures can all be handled by hand. It is mainly provided to make the specific case of point sets simpler to handle. Users can still add their own features within their feature set.
The following snippet shows how to use the feature generator:
Classification relies on a classifier: this classifier is an object that, from the set of values taken by the features at an input item, computes the energy that measures the likelihood of an input item to belong to one label or another. A model of the concept CGAL::Classification::Classifier must take the index of an input item and store the energies associated to each label in a vector. If a classifier returns the value 0 for a pair of label and input item, it means that this item belongs to this label with certainty; large values mean that this item is not likely to belong to this label.
This first classifier defines the following attributes:
a weight applied to each feature;
an effect applied to each pair of feature and label.
For each label, the classifier computes the energy as a sum of features normalized with both their weight and the effect they have on this specific label.
This classifier can be set up by hand but also embeds a training algorithm.
Weights and Effects
Each feature is assigned a weight that measures its strength with respect to the other features.
Each pair of feature and label is assigned an effect that can either be:
FAVORING: the label is favored by high values of the feature;
NEUTRAL: the label is not affected by the feature;
PENALIZING: the label is favored by low values of the feature.
For example, vegetation is expected to have a high distance to plane and have a color close to green (if colors are available); facades have a low distance to plane and a low verticality; etc.
Let \(x=(x_i)_{i=1..N}\) be a potential classification result with \(N\) the number of input items and \(x_i\) the class of the \(i^{th}\) item (for example: vegetation, ground, etc.). Let \(f_j(i)\) be the raw value of the \(j^{th}\) feature at the \(i^{th}\) item and \(w_j\) be the weight of this feature. We define the normalized value \(F_j(x_i) \in [0:1]\) of the \(j^{th}\) feature at the \(i^{th}\) item as follows:
Each feature has a specific weight and each pair of feature-label has a specific effect. This means that the number of parameters to set up can quickly explode: if 6 features are used to classify between 4 labels, 30 parameters have to be set up (6 weights + 6x4 feature-label relationships).
Though it is possible to set them up one by one, CGAL also provides a method train() that requires a small set of ground truth items provided by users. More specifically, users must provide, for each label they want to classify, a set of known inliers among the input data set (for example, selecting one roof, one tree and one section of the ground). The training algorithm works as follows:
for each feature, a range of weights is tested: the effect each feature have on each label is estimated. For a given weight, if a feature has the same effect on each label, it is non-relevant for classification. The range of weights such that the feature is relevant is estimated;
for each feature, uniformly picked weight values are tested and their effects estimated;
each inlier provided by the user is classified using this set of weights and effects;
the mean intersection-over-union (see Evaluation) is used to evaluate the quality of this set of weights and effects;
the same mechanism is repeated until all features' ranges have been tested. Weights are only changed one by one, the other ones kept to the values that gave the latest best score.
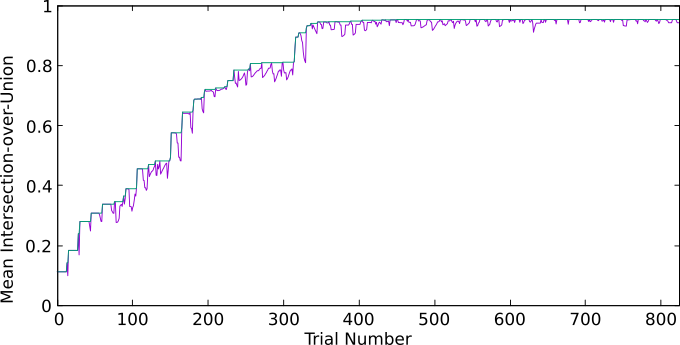
This usually converges to a satisfying solution (see Figure Figure 74.2). The number of trials is user defined, set to 300 by default. Using at least 10 times the number of features is advised (for example, at least 300 iterations if 30 features are used). If the solution is not satisfying, more inliers can be selected, for example, in a region that the user identifies as misclassified with the current configuration. The training algorithm keeps, as initialization, the best weights found at the previous round and carries on trying new weights by taking new inliers into account.
Figure 74.2 Example of evolution of the mean intersection-over-union. The purple curve is the score computed at the current iteration, green curve is the best score found so far.
Result
Figure Figure 74.3 shows an example of output on a defect-laden point set. The accuracy on this example is 0.97 with a mean intersection-over-union of 0.85 (see section Evaluation).
Figure 74.3 Example of classification on a point set with medium noise and outliers (left: input, right: output). Ground is orange, roofs are pink, vegetation is green. Outliers are classified with an additional label outlier in black.
ETHZ Random Forest
CGAL provides ETHZ_random_forest_classifier, a classifier based on the Random Forest Template Library developed by Stefan Walk at ETH Zurich [2] (the library is distributed under the MIT license and is included with the CGAL release, the user does not have to install anything more). This classifier uses a ground truth training set to construct several decision trees that are then used to assign a label to each input item.
This classifier cannot be set up by hand and requires a ground truth training set. The training algorithm is significantly faster but usually requires a higher number of inliers than the previous classifier. The training algorithm uses more memory at runtime and the configuration files are larger than those produced by Sum_of_weighted_features_classifier, but the output quality is usually significantly better, especially in the cases where many labels are used (more than five).
An example shows how to use this classifier. For more details about the algorithm, please refer to README provided in the ETH Zurich's code archive.
It is provided for the sake of completeness and for testing purposes, but if you are not sure what to use, we advise using the ETHZ Random Forest instead.
An example shows how to use this classifier. For more details about the algorithm, please refer to the official documentation of OpenCV.
Classification Functions
Classification is performed by minimizing an energy over the input data set that may include regularization. CGAL provides three different methods for classification, ranging from high speed / low quality to low speed / high quality:
On a point set of 3 millions of points, the first method takes about 4 seconds, the second about 40 seconds and the third about 2 minutes.
Figure 74.4 Top-Left: input point set. Top-Right: raw output classification represented by a set of colors (ground is orange, facades are blue, roofs are pink and vegetation is green). Bottom-Left: output classification using local smoothing. Bottom-Right: output classification using graphcut.
Let \(x=(x_i)_{i=1..N}\) be a potential classification result with \(N\) the number of input items and \(x_i\) the label of the \(i^{th}\) item (for example: vegetation, ground, etc.). The classification is performed by minimizing the following energy:
\[ E(x) = \sum_{i = 1..N} E_{di}(x_i) \]
This energy is a sum of itemwise energies provided by the classifier and involves no regularization.
The following snippets show how to classify points based on a label set and a classifier. The result is stored in label_indices, following the same order as the input set and providing for each point the index (in the label set) of its assigned label.
This allows to eliminate local noisy variations of assigned labels. Increasing the size of the neighborhood increases the noise reduction at the cost of higher computation times.
std::cerr << "Classification with local smoothing performed in " << t.time() << " second(s)" << std::endl;
t.reset();
Global Regularization (Graph Cut)
CGAL::Classification::classify_with_graphcut(): this method offers the best quality but requires longer computation time (see Figure Figure 74.4, bottom-right). The total energy that is minimized is the sum of the partial data term \(E_{di}(x_i)\) and of a pairwise interaction energy defined by the standard Potts model [5] :
where \(\gamma>0\) is the parameter of the Potts model that quantifies the strengh of the regularization, \(i \sim j\) represents the pairs of neighboring items and \(\mathbf{1}_{\{.\}}\) the characteristic function.
A Graph Cut based algorithm (Alpha Expansion) is used to quickly reach an approximate solution close to the global optimum of this energy.
This method allows to consistently segment the input data set in piecewise constant parts and to correct large wrongly classified clusters. Increasing \(\gamma\) produces more regular result with a constant computation time.
To speed up computations, the input domain can be subdivided into smaller subsets such that several smaller graph cuts are applied instead of a big one. The computation of these smaller graph cuts can be done in parallel. Increasing the number of subsets allows for faster computation times but can also reduce the quality of the results.
The following snippet shows how to classify points using a graph cut regularization providing a model of CGAL::Classification::NeighborQuery, a strengh parameter \(\gamma\) and a number of subdivisions.
std::cerr << "Classification with graphcut performed in " << t.time() << " second(s)" << std::endl;
Evaluation
The class Evaluation allows users to evaluate the reliability of the classification with respect to a provided ground truth. The following measurements are available:
precision() computes, for one label, the ratio of true positives over the total number of detected positives;
recall() computes, for one label, the ratio of true positives over the total number of provided inliers of this label;
f1_score() is the harmonic mean of precision and recall;
intersection_over_union() computes the ratio of true positives over the union of the detected positives and of the provided inliers;
accuracy() computes the ratio of all true positives over the total number of provided inliers;
classifies the point set with the 3 different methods (this is for the sake of the example: each method overwrites the previous result, users should only call one of the methods);




 1.8.13
1.8.13