
|
CGAL 6.2 - Quadtrees, Octrees, and Orthtrees
|
Loading...
Searching...
No Matches
|
CGAL 6.2 - Quadtrees, Octrees, and Orthtrees
|
Quadtrees are tree data structures in which each node encloses a rectangular section of space, and each internal node has exactly 4 children. Octrees are a similar data structure in 3D in which each node encloses a rectangular cuboid section of space, and each internal node has exactly 8 children.
We call the generalization of such data structure "orthtrees", as orthants are generalizations of quadrants and octants. The term "hyperoctree" can also be found in literature to name such data structures in dimensions 4 and higher.
This package provides a general data structure Orthtree along with aliases for Quadtree and Octree. These trees can be constructed with custom contents and split predicates, and iterated on with various traversal methods. Orthants can be orthotopes and not only hypercubes.
 |
 |
Figure 104.1 Top: an orthtree in 3D (octree) from a point cloud (top); Bottom: an orthtree in 3D (octree) from the triangle faces of a mesh.
A common purpose for an orthtree is to subdivide a collection of points, and the Orthtree package provides a traits class for this purpose. The points are not copied: the provided point range is used directly and rearranged by the orthtree. Altering the point range after creating the orthtree may leave the tree in an invalid state. The constructor returns a tree with a single (root) node that contains all the points.
The method refine() must be called to subdivide space further. This method uses a split predicate which takes a node as input and returns true if this node should be split, false otherwise: this enables users to choose on what criterion should the orthtree be refined. Predefined predicates are provided for the point-set orthtree, including Maximum_depth and Maximum_contained_elements.
The simplest way to create a point-set orthtree is from a vector of points. The constructor generally expects a separate point range and map, but the point map defaults to Identity_property_map if none is provided.
The split predicate is a user-defined functor that determines whether a node needs to be split. Custom predicates can easily be defined if the existing ones do not match users' needs.
The Orthtree class may be templated with Orthtree_traits_point<> while specifying a 2d ambient space and thus behave as a quadtree. For convenience, the alias CGAL::Quadtree is provided.
The following example shows the construction of quadtree from a vector of Point_2 objects. quadtree.refine(10, 5) uses the default split predicate, which enforces a max-depth and a maximum of elements contained per node ("bucket size"). Nodes are split if their depth is less than 10, and they contain more than 5 points.
Example: Orthtree/quadtree_build_from_point_vector.cpp
Orthtree_traits_point<> can also be templated with dimension 3 and thus behave as an octree. For convenience, the alias CGAL::Octree is provided.
The following example shows how to create an octree from a vector of Point_3 objects. As with the quadtree example, we use the default split predicate. In this case the maximum depth is 10, and the bucket size is 1.
Example: Orthtree/octree_build_from_point_vector.cpp
Some data structures such as Point_set_3 require a non-default point map type and object. This example illustrates how to create an octree from a Point_set_3 loaded from a file. It also shows a more explicit way of setting the split predicate when refining the tree.
An octree is constructed from the point set and its corresponding map, and then written to the standard output.
The split predicate is manually constructed and passed to the refine method. In this case, we use a maximum number of contained elements with no corresponding maximum depth. This means that nodes will continue to be split until none contain more than 10 points.
Example: Orthtree/octree_build_from_point_set.cpp
The following example illustrates how to refine an octree using a split predicate that isn't provided by default. This particular predicate sets a node's bucket size as a ratio of its depth. For example, for a ratio of 2, a node at depth 2 can hold 4 points, a node at depth 7 can hold 14.
Example: Orthtree/octree_build_with_custom_split.cpp
An orthtree can also be used with an arbitrary number of dimensions. The Orthtree_traits_point template can infer the arbitrary dimension count from the d-dimensional kernel.
The following example shows how to build a generalized orthtree in dimension 4. As std::vector<Point_d> is manually filled with 4-dimensional points. The vector is used as the point set, and an Identity_property_map is automatically set as the orthtree's map type, so a map does not need to be provided.
Example: Orthtree/orthtree_build.cpp
The Orthtree uses a mechanism to attach properties to nodes at run-time which follows Surface mesh properties. Each property is identified by a string and its value type and stored in a consecutive block of memory.
Traversal is the act of navigating among the nodes of the tree. The Orthtree class provides a number of different solutions for traversing the tree.
Because our orthtree is a form of connected acyclic undirected graph, it is possible to navigate between any two nodes. What that means in practice is that given a node on the tree, it is possible to access any other node using the right set of operations. The Node_index type provides a handle on a node, and the orthtree class provides methods that enable the user to retrieve the indices of each of its children as well as its parent (if they exist).
Given any node index nid, the nth child of that node can be found with orthtree.child(nid, n). For an octree, values of n from 0-7 provide access to the different children. For non-root nodes, it is possible to access parent nodes using the orthtree.parent() accessor.
To access grandchildren, it isn't necessary to use nested orthtree.child() calls. Instead, the orthtree.descendant(node, a, b, ...) convenience method is provided. This retrieves the bth child of the ath child, to any depth.
In most cases, we want to find the descendants of the root node. For this case, there is another convenience method orthtree.node(a, b, c, ...). This retrieves the node specified by the descent a, b, c. It is equivalent to orthtree.descendant(orthtree.root(), a, b, c, ...).
The following example demonstrates the use of several of these accessors.
Example: Orthtree/octree_traversal_manual.cpp
It is often useful to be able to iterate over the nodes of the tree in a particular order. For example, the stream operator << uses a traversal to print out each node. A few traversals are provided, among them Preorder_traversal and Postorder_traversal. Traversing a tree in preorder means to visit each parent immediately followed by its children, whereas in postorder traversal the children are visited first.
The following example illustrates how to use the provided traversals.
A tree is constructed, and a traversal is used to create a range that can be iterated over using a for-each loop. The default output operator for the orthtree uses the preorder traversal to do a pretty-print of the tree structure. In this case, we print out the nodes of the tree without indentation instead.
Example: Orthtree/octree_traversal_preorder.cpp
Users can define their own traversal methods by creating models of the OrthtreeTraversal concept. The custom traversal must provide a method which returns the starting point of the traversal (first_index()) and another method which returns the next node in the sequence (next_index()). next_index() returns an empty optional when the end of the traversal is reached. The following example shows how to define a custom traversal that only traverses the first branch an octree:
Example: Orthtree/octree_traversal_custom.cpp
Figure 104.2 shows in which order nodes are visited depending on the traversal method used.
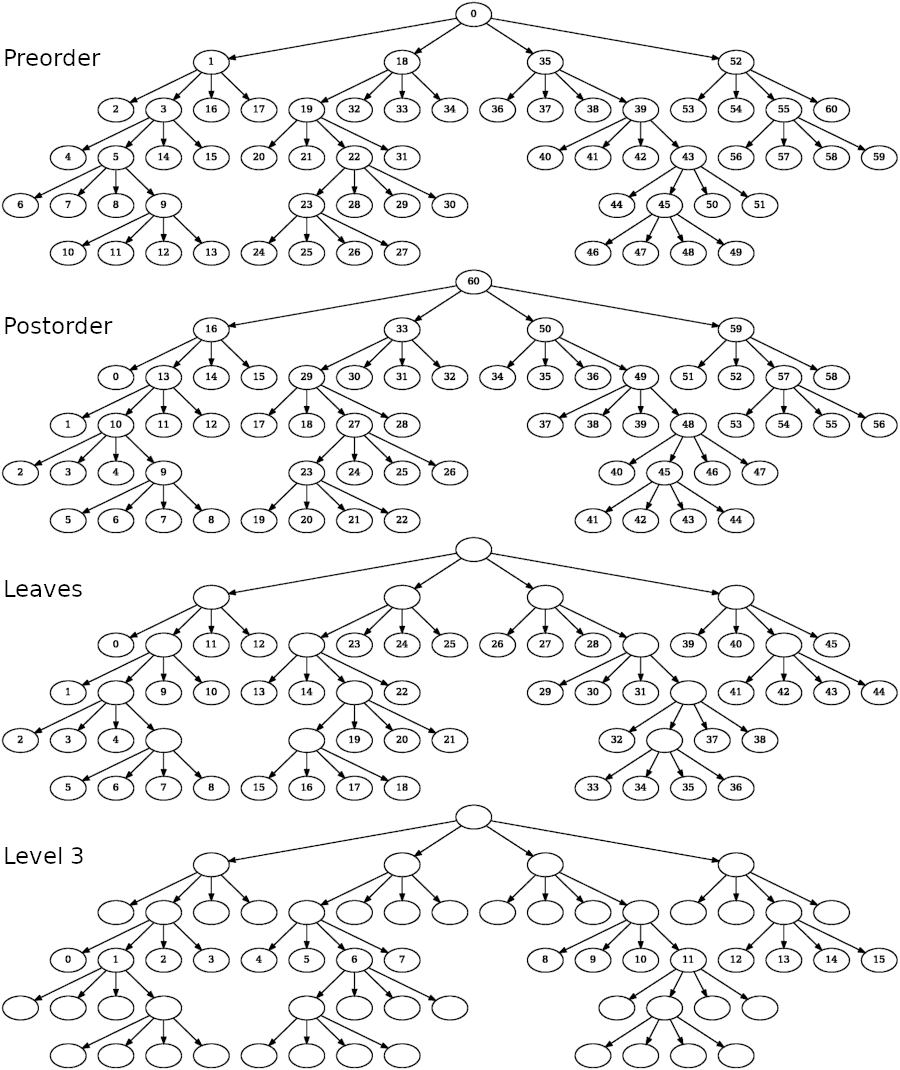
Figure 104.2 Quadtree visualized as a graph. Each node is labeled according to the order in which it is visited by the traversal. When using leaves and level traversals, the quadtree is only partially traversed.
Once an orthtree is built, its structure can be used to accelerate different tasks.
The naive way of finding the nearest neighbor of a point requires finding the distance to all elements. An orthtree can be used to perform the same task in significantly less time. For large numbers of elements, this can be a large enough difference to outweigh the time spent building the tree.
Note that a kd-tree is expected to outperform the orthtree for this task on points, it should be preferred unless features specific to the orthtree are needed.
The following example illustrates how to use an octree to accelerate the search for points close to a location.
Points are loaded from a file and an octree is built. The nearest neighbor method is invoked for several input points. A k value of 1 is used to find the single closest point. Results are put in a vector, and then printed.
Example: Orthtree/octree_find_nearest_neighbor.cpp
Not all octrees are compatible with nearest neighbor functionality, as the idea of a nearest neighbor may not make sense for some tree contents. For the nearest neighbor methods to work, the traits class must implement the CollectionPartitioningOrthtreeTraits concept.
An orthtree is considered "graded" if the difference of depth between two adjacent leaves is at most 1 for every pair of leaves.
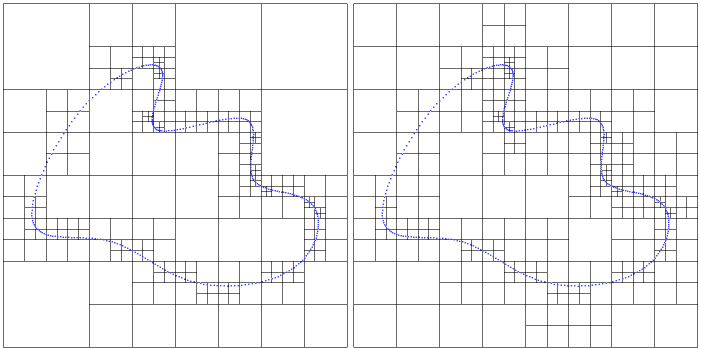
Figure 104.3 Quadtree before and after being graded.
The following example demonstrates how to use the grade method to eliminate large jumps in depth within the orthtree.
A tree is created such that one node is split many more times than those it borders. grade() splits the octree's nodes so that adjacent nodes never have a difference in depth greater than one. The tree is printed before and after grading, so that the differences are visible.
Example: Orthtree/octree_grade.cpp
Tree construction benchmarks were conducted by randomly generating a collection of points, and then timing the process of creating a fully refined tree which contains them.
Because of its simplicity, an octree can be constructed faster than a kd-tree.
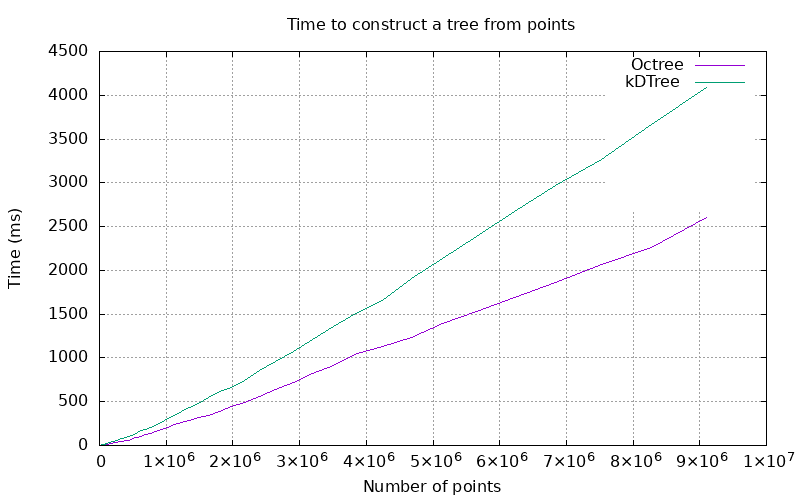
Figure 104.4 Plot of the time to construct a tree.
Orthtree nodes are uniform, so orthtrees will tend to have deeper hierarchies than equivalent kd-trees. As a result, orthtrees will generally perform worse for nearest neighbor searches. Both nearest neighbor algorithms have a theoretical complexity of \(O(log(n))\), but the orthtree can generally be expected to have a higher coefficient.
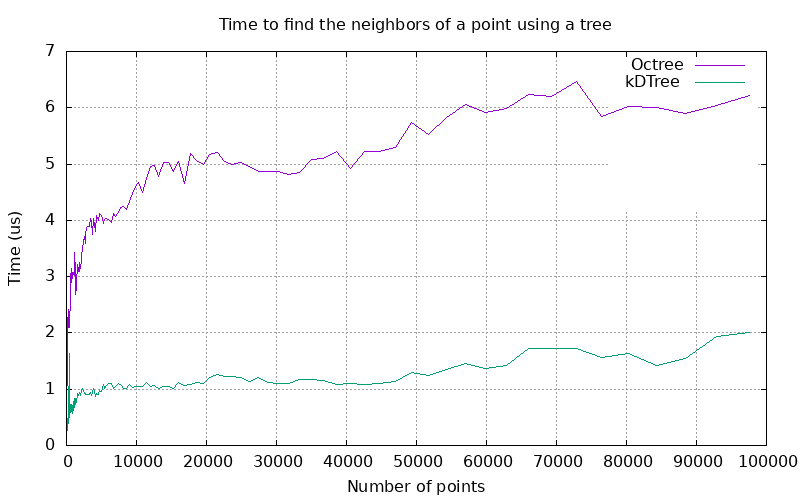
Figure 104.5 Plot of the time to find the 10 nearest neighbors of a random point using a pre-constructed tree.
The performance difference between the two trees is large, but both algorithms compare very favorably to the linear complexity of the naive approach, which involves comparing every point to the search point.
Using the orthtree for nearest neighbor computations instead of the kd-tree can be justified either when few queries are needed (as the construction is faster) or when the orthtree is also needed for other purposes.
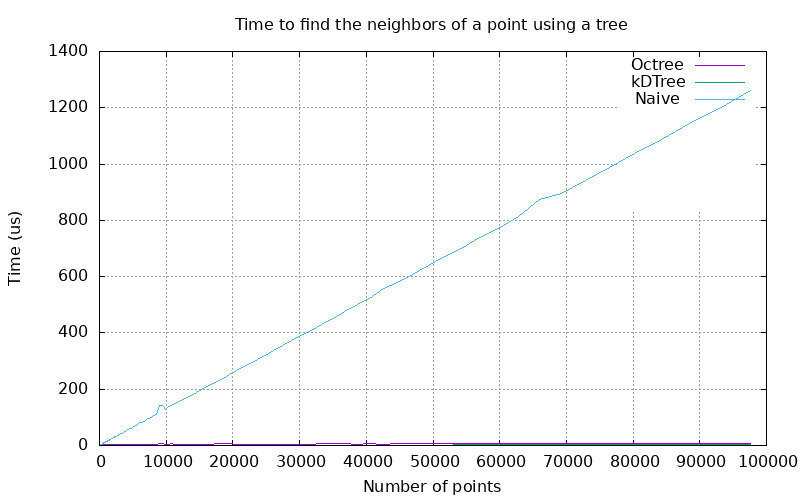
Figure 104.6 Plot of the time to find nearest neighbors using tree methods and a naive approach.
For nontrivial point counts, the naive approach's calculation time dwarfs that of either the orthtree or kd-tree.
The orthtree package changed to allow for custom data stored per node in the orthtree. To migrate existing code written before CGAL 6.0 Orthtree_traits_point can be used for a point-based orthtrees. The aliases CGAL::Quadtree and CGAL::Octree have been extended by a boolean template parameter to allow for non-cubic cells, which is the default. The data is passed via the traits class and no longer directly to the orthtree.
Former code to declare and define an Octree with cubic cells was as follows:
CGAL 6.0 code with identical behavior is now:
The node class does not exist anymore and has been replaced by the lightweight type Node_index. All information formerly contained in the node class is now accessible via the Orthtree interface.
Former node access was as follows:
CGAL 6.0 node access is now:
The nearest neighbor search behaves as before, however, the output iterator will be required to store CollectionPartitioningOrthtreeTraits::Node_data_element. This may be the actual point or, e.g., in case a Point_set_3 is used, an index which requires the use of a point map to retrieve the point.
The provided traversals, i.e., CGAL::Orthtrees::Leaves_traversal, CGAL::Orthtrees::Preorder_traversal, CGAL::Orthtrees::Postorder_traversal, require the orthtree as template parameter now.
Former traversal use was as follows:
CGAL 6.0 traversal use is now:
A prototype code was implemented by Pierre Alliez and improved by Tong Zhao and Cédric Portaneri. From this prototype code, the package was developed by Jackson Campolattaro as part of the Google Summer of Code 2020. Simon Giraudot, supervisor of the GSoC internship, completed and finalized the package for integration in CGAL 5.3. Pierre Alliez provided kind help and advice all the way through. Starting with CGAL 6.0 an API improvement of the Orthtree package was released. Most notably, the orthtree nodes do not need to store anything. Data to be stored by the node are managed through a mechanism of dynamic properties. This improvement was done by Jackson Campolattaro thanks to a funding provided by INRIA, together with GeometryFactory.